Organizzare e ricercare le fonti digitali: il progetto RepubLit
Università del Piemonte Orientale “Amedeo Avogadro”
1. Nel mondo globalizzato e reso
interconnesso dalla fitta trama delle reti telematiche, il ruolo esercitato
dalle fonti digitali nell’attività di ricerca è sempre
più rilevante. Il web, oggi,
è diventato il grande archivio da esplorare. Le ripercussioni sul lavoro
storiografico, in particolare l’esigenza di una nuova critica delle fonti
digitali, hanno alimentato una riflessione metodologica ricca di voci
significative. Con altrettanta evidenza, peraltro, si è manifestata la
necessità di disporre di mezzi tecnologici mediante i quali sfruttare
pienamente la grande quantità di documenti in formato
elettronico.
Nello scenario della rete, plasmato da Google nell’ultimo decennio, lo
strumento a cui affidare questo compito non può che essere un motore di
ricerca.
L’ambito umanistico, per le peculiarità che lo
distinguono dalle altre discipline, è forse quello che più risente
della carenza di realtà appositamente dedicate. Non sono mancati i
tentativi in questa direzione – il riferimento è ai Limited Area Search Engines –
mai usciti però del tutto dal terreno della sperimentazione, per non dire
della provvisorietà.
Unificare l’accesso alle risorse
telematiche, nel quadro di uno strumento pensato per ricercarle e gestirle con
la massima efficienza, è a nostro avviso un obiettivo
strategico.
2. Progettare un tale strumento, pensato da ricercatori
per un’utenza di ricercatori, è senz’altro una sfida
affascinante. Creare le condizioni migliori per misurarsi con essa implica
probabilmente il ricorso a mezzi in parte diversi da quelli tipici di chi fa
ricerca accademica.
La ricerca applicata necessita di modalità
operative, e conseguentemente di uno status giuridico, peculiari. La governance del mondo universitario ha
dato una risposta a queste esigenze incentivando il ricorso a uno specifico
strumento: lo ‘spin-off accademico’, ossia un’impresa innovativa che nasce dalla ricerca
condotta nelle università.
Il mondo accademico, favorendo la
creazione di realtà imprenditoriali da parte di figure appartenenti al
personale universitario, dà attuazione alle sue finalità
istituzionali promuovendo il trasferimento al mercato dei risultati della
ricerca effettuata al proprio interno. Presso l’Università del
Piemonte Orientale “Amedeo Avogadro”, dove chi scrive è
titolare di un assegno di ricerca, è in vigore un apposito regolamento
che all’art. 1 stabilisce quanto segue:
Lo strumento Spin-off si propone di favorire il contatto tra le strutture di ricerca universitarie, il mondo produttivo e le istituzioni del territorio al fine di sostenere l’attività di ricerca e diffondere tecnologie, con positivi effetti sulla produzione industriale, sul benessere sociale e sull’attrattività del territorio per investimenti nazionali ed internazionali.
3. Da queste premesse è sorta RepubLit. Il nome della società
(pronunciato analogamente all’inglese ‘republic’) evoca la
creazione di un’unica comunità del sapere – versione moderna
della Respublica Litterarum –
nei cui confronti essa si propone come punto di riferimento nell’ambiente
telematico.
La nuova impresa, fondata e amministrata da chi scrive,
è stata approvata con delibera del consiglio d’amministrazione di
ateneo il 18 luglio 2008 e costituita come società a
responsabilità limitata con atto notarile del 5 marzo 2009.
Gli
obiettivi che ci siamo posti con questo progetto – anticipato a suo tempo
dalle pagine di Cromohs[1] – richiedono investimenti che, per ordine di grandezza e durata nel tempo,
non sono compatibili con i normali canali di finanziamento alla ricerca. Il
tratto comune a tutte le esperienze precedenti è il collo di bottiglia
rappresentato dalle modalità di sovvenzione: numerosi esempi dimostrano
che i fondi pubblici per la ricerca sono ideali per avviare un progetto (laddove
il privato talvolta non investirebbe) ma sono strutturalmente inadatti a
sostenerlo nel medio-lungo periodo. D’altro canto, le prospettive di
ricadute sul mondo produttivo che questa iniziativa porta con sé sono
tali da motivare il ricorso a questa opzione. Intendiamo aprire una nuova strada
su un terreno sconosciuto – ma che studiosi di altre facoltà
percorrono con successo da anni – testimoniando così la
capacità degli umanisti di proporre idee che abbiano un impatto virtuoso
sul circuito economico.
4. Nei primi mesi di vita di questa nuova
realtà, gli obiettivi prima enunciati sono stati tradotti in uno studio
di fattibilità di cui daremo conto in queste pagine.
L’attività di ricerca, che ha gettato le basi per le successive
fasi di sviluppo, è stata parzialmente finanziata grazie a un contributo
erogato dal Programma FIxO (Formazione e Innovazione per l’Occupazione)
del Ministero del Lavoro, che tra le sue linee di intervento includeva
“Azioni formative e di accompagnamento per l’avvio di spin-off
accademici”. Nell’ambito del Programma FIxO alcuni validi
collaboratori hanno messo a disposizione di RepubLit le loro competenze: Fulvio
Corno, professore associato di informatica presso il Politecnico di Torino e
studioso del semantic web; Luca
Rosati, esperto di architettura dell’informazione e docente
all’Università di Perugia; lo staff di Intellisemantic S.r.l., una start-up altamente innovativa guidata
da Alberto Ciaramella[2]. Inquadrato l’obiettivo finale – realizzare un
motore di ricerca umanistico, concepito espressamente per una utenza accademica,
e dotato di strumenti avanzati di interrogazione, selezione e filtro dei
documenti – il problema delle fonti e del loro trattamento è stato
posto come aspetto centrale della sperimentazione, attuata nel corso del
2009.
Dal punto di vista delle modalità di pubblicazione, il web umanistico si caratterizza per la
compresenza di fonti strutturate e di fonti non strutturate. Alle
prime appartengono le banche dati
editoriali con accesso a pagamento, contenenti riviste elettroniche o collezioni
di testi digitalizzati; a questo gruppo appartengono altresì le
iniziative ad accesso aperto, come i repositories istituzionali sviluppati
nell’ambito della Open Archives
Initiative[3] e i periodici elencati nella Directory of Open Access
Journals[4]. Benché siano
caratterizzate da politiche editoriali molto diverse, queste risorse hanno in
comune il fatto che i dati sono accompagnati da metadati: si tratta dunque di
fonti strutturate, a differenza invece di una serie di risorse (organizzate in
siti web tematici tutti ad accesso
gratuito) che contengono testi e materiali destinati alla ricerca scientifica ma
che vengono immesse in rete senza un corredo di metadati. Riprendendo tale distinzione, gli obiettivi che ci siamo
posti consistono nell’organizzare al meglio la ricerca all’interno
dei documenti strutturati; e nello strutturare quelli che non lo sono, per
renderli a loro volta efficacemente ricercabili.
5. Per conferire
struttura a un testo occorre ottenere informazioni caratterizzanti su di esso.
È stata perciò studiata una procedura mediante la quale ricavare i
concetti-chiave di ciascun documento. Il progetto prevede che i lemmi
significativi, presenti nei documenti indicizzati dal motore di ricerca, vengano
organizzati in specifiche aree tematiche. Trattandosi di un motore verticale di
taglio umanistico, le aree individuate sono: Persone (studiosi, autori
letterari, personaggi storici); Argomenti (concetti periodizzanti, ambiti
subdisciplinari ecc.); Periodi (suddivisi in decadi); Luoghi (stati, regioni,
città ecc.).
La conseguenza naturale di questo approccio è
stata la scelta di adottare la faceted
search come modalità di visualizzazione dei risultati delle
ricerche. Tale modalità si basa sulla classificazione
analitico-sintetica, o a faccette, la quale prevede che ciascun documento sia
descritto secondo vari punti di vista, o
sfaccettature[5]. Ampiamente utilizzata nel web, è stata definita come il
punto di convergenza tra i due consolidati paradigmi della ricerca online: la navigazione
all’interno di tassonomie e repertori di siti organizzati gerarchicamente,
e la ricerca diretta nel testo delle pagine web tramite i search
engines[6]. La faceted
search è in grado di combinare entrambi gli approcci e rappresenta
lo stato dell’arte in svariati settori:
dall’e-commerce, dove ha trovato
la sua prima applicazione, fino alle interfacce di molti cataloghi bibliografici
informatizzati. Più recentemente, però, questo modello è
stato fatto proprio, in qualche misura, anche da Bing, il nuovo motore di ricerca di Microsoft, e dallo stesso Google dopo la profonda
riorganizzazione della sua interfaccia di ricerca
(online dal maggio 2010). La faceted search si è dunque
rivelata lo schema di interazione uomo-macchina che meglio si adatta ai
presupposti del nostro progetto. Le quattro ‘faccette’ che abbiamo individuato
rappresentano altrettanti punti di vista da cui guardare un documento. Portare
in superficie i concetti racchiusi nel testo è stato pertanto il primo
criterio elaborato per classificare i documenti. Il secondo criterio prescinde
invece dal contenuto e consiste nel classificarli in base alla loro tipologia,
alla lingua e al formato utilizzati.
Una volta adottati questi principi,
è stata progettata una interfaccia di ricerca che offre due opzioni
complementari per la navigazione all’interno dei risultati: refinement e filtering, corrispondenti
rispettivamente al primo e al secondo criterio testé
elencati.
6. La sperimentazione ha quindi comportato la realizzazione di una interfaccia utente, mediante la quale sono visualizzabili le effettive modalità di funzionamento del motore di ricerca. Occorre subito precisare che si tratta di una demo statica, pertanto non vi è al momento la possibilità di effettuare ulteriori prove. Le immagini seguenti, accompagnate da commenti esplicativi, sono state catturate dal sito web su cui la demo è stata caricata.

Fig. I. Lo scopo di RepubLit è condurre l’utente fino al contenuto che soddisfa le sue esigenze di studio o di ricerca. Nell’esempio in figura, un utente sta cercando informazioni sul filosofo austriaco Ludwig Wittgenstein. Egli accede alla home page e digita “Wittgenstein” nella maschera di ricerca, quindi preme il tasto “Search”.
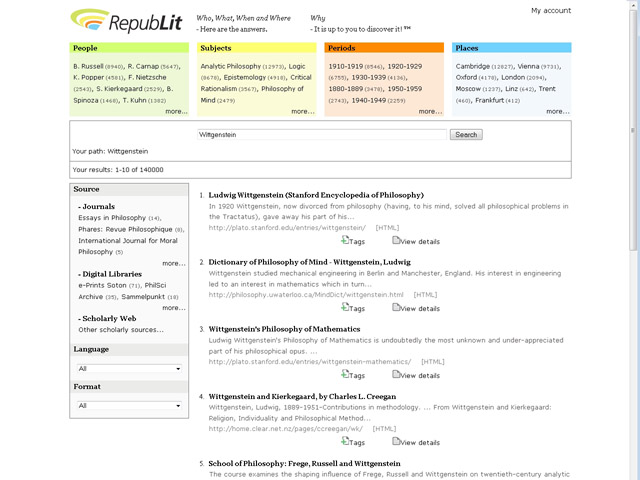
Fig. II. Quella che viene ora mostrata è la pagina dei risultati. L’interfaccia di RepubLit è dotata di caratteristiche innovative che la distinguono dagli altri motori di ricerca, e dispone di strumenti per selezionare e filtrare le risorse più valide. La schermata dei risultati è divisa funzionalmente in tre parti: le aree tematiche, i filtri, e i risultati veri e propri.
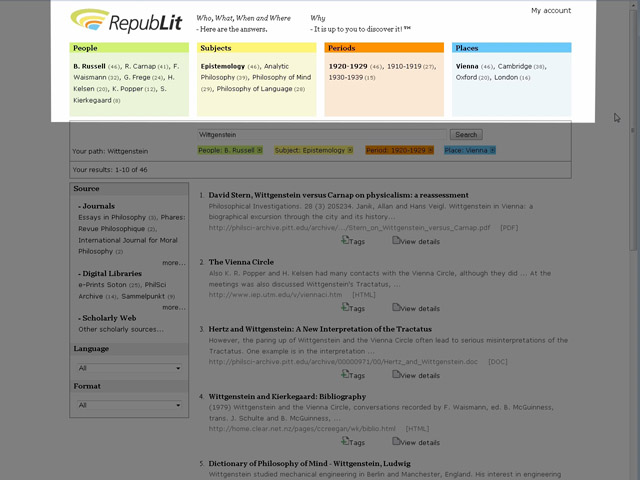
Fig.
III. Nella parte superiore della pagina si trovano quattro clusters, suddivisi per area tematica
(People, Subjects, Periods, Places). Il motore di ricerca analizza
i documenti indicizzati ed estrae dal testo i termini riferibili a questi
quattro campi semantici. Utilizzando la terminologia biblioteconomica, tali
termini sono definiti come i ‘fuochi’ di ciascuna
‘faccetta’.
Ad ogni interrogazione del motore di ricerca, i
fuochi visualizzati nei clusters saranno sempre diversi: in base alle keywords utilizzate nella query corrente, di volta in volta
compariranno soltanto i termini correlati, ossia quelli presenti negli stessi
documenti in cui compaiono anche le keywords scelte dall’utente
(ordinati in base al numero di occorrenze, indicato tra parentesi).
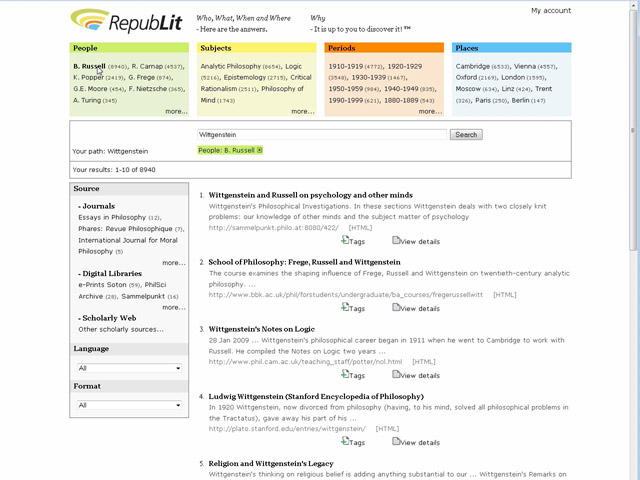
Fig.
IV. Cliccando su un termine (per esempio, nel riquadro People, su “B. Russell”),
la correlazione individuata dal motore di ricerca viene esplicitata
dall’utente stesso. Ciò che si ottiene è un raffinamento:
una label dello stesso colore viene
aggiunta nel search path e i risultati
si restringono ai soli documenti che contengono sia Wittgenstein sia Russell.
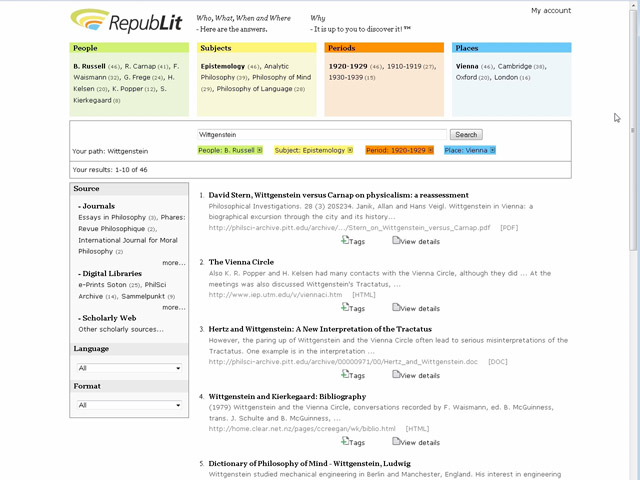
Fig. V.
La stessa operazione può essere ripetuta più volte, selezionando o
deselezionando termini in ciascuna area. Nell’esempio vengono selezionati
“Epistemology” in Subjects, “Vienna” in Places e la decade
“1920-1929” in Periods. Le
possibilità di riorganizzare i risultati, individuando nuovi percorsi di
ricerca, sono praticamente illimitate. A questo allude la tagline, ovvero la frase che campeggia
in alto, accanto al logo:
Who, What,
When, and Where – Here are the
answers. Why – It is up to you
to discover it!

Fig.
VI. L’utente ha sempre il controllo su tutte le operazioni. Per
esempio, può decidere che il luogo non è funzionale alla sua
ricerca, mentre è più importante individuare altre persone
collegate a Wittgenstein. Deseleziona perciò “Vienna”, ed
espande la faccetta People.
I
termini estratti dal motore di ricerca sono molti di più dei dieci
visualizzati nei riquadri: il tasto “more...” consente di espandere
ciascuna faccetta in una finestra che si sovrappone alla pagina, mostrando fino
a cento termini, ordinati alfabeticamente o per numero di occorrenze.
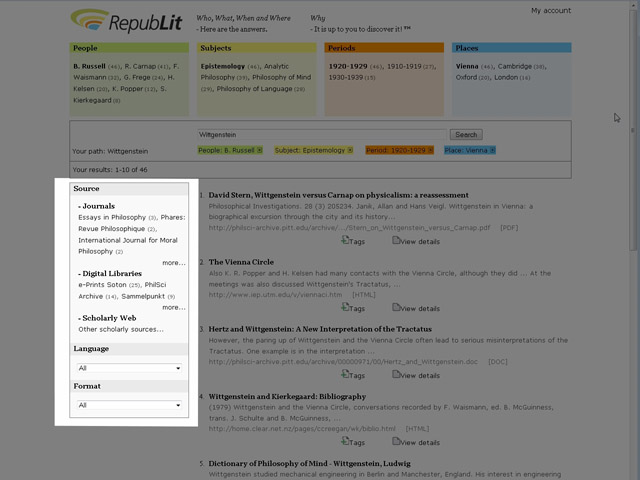
Fig.
VII. Il motore di ricerca è in grado anche di selezionare i
documenti per tipologia. Nel frame sinistro, accanto ai risultati, trovano posto i filtri che consentono di
esplorare i risultati con questa modalità. L’intero indice di RepubLit è organizzato in
categorie. La principale è Sources: tutti i documenti indicizzati
sono suddivisi, per facilitarne la reperibilità, in tre tipologie di
fonti – riviste scientifiche, collezioni di testi digitalizzati, altre
risorse appartenenti al web accademico.
L’utente ha inoltre a disposizione altri due filtri, Format e Language, che gli consentono di
selezionare, per esempio, documenti solo in .pdf, o solo in tedesco.
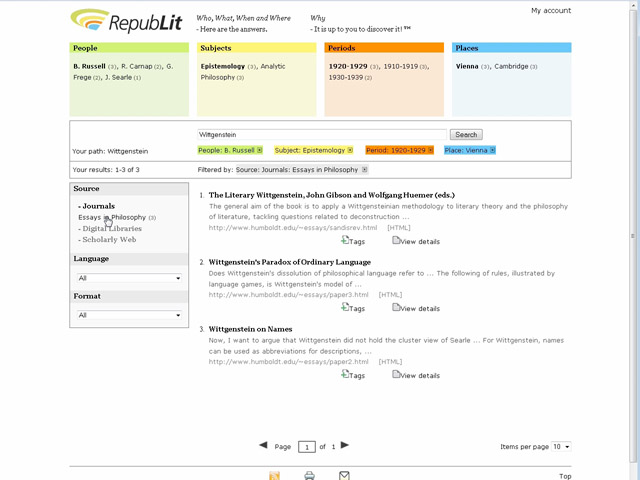
Fig.
VIII. Il filtering è
gestito in modo analogo al raffinamento semantico. L’utente può
decidere, per esempio, di restringere la sua ricerca alle sole riviste,
selezionando Journals; ma può
anche scendere a un livello più dettagliato, selezionando direttamente la
singola rivista. Anche in questo caso il search path traccia le operazioni
svolte dall’utente, aggiungendo una nuova label. Questo discorso si applica
ovviamente anche a Digital Libraries;
non è previsto invece per le risorse non strutturate
(Scholarly
Web).
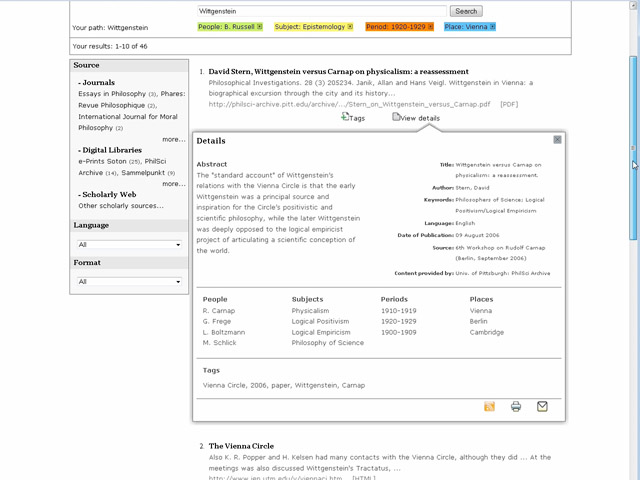
Fig.
IX. Con RepubLit l’utente
può selezionare e filtrare i contenuti, ma anche gestirli. Accanto a ogni
risultato sono presenti due icone, “Tags” e “View
Details”. Grazie alla prima l’utente può aggiungere quel
risultato ai preferiti nel suo account personale, assegnandogli eventualmente delle etichette
(tags). “View Details”,
invece, svolge la funzione che ha l’indice analitico in una pubblicazione
cartacea: riepiloga tutti i termini correlati limitatamente a quel documento,
dando una panoramica sul suo contenuto prima ancora di aprirlo; evidenzia i
metadati, qualora siano disponibili; visualizza i tags assegnati dall’utente.
In sintesi, RepubLit
a. propone nuove
ricerche sulla base dell’estrazione semantica di contenuti correlati;
b. consente di navigare tra i risultati, filtrandoli per tipologia, lingua
e formato;
c. offre una breve scheda analitica di ogni singola
risorsa.
7. Il design dell’interfaccia non è stato però l’unico output della sperimentazione
effettuata. A livello progettuale sono state affrontate altre questioni,
strettamente intrecciate tra di loro ma comunque inquadrabili in quattro
principali linee di ricerca.
La prima riguarda il problema cruciale
dell’estrazione di informazioni da testi non strutturati: nel nostro caso,
di lemmi riconducibili a precisi campi semantici (le ‘faccette’).
Tale operazione, che equivale, secondo la corrispondente teoria
biblioteconomica, a popolare le ‘faccette’ con i relativi
‘fuochi’, può essere effettuata attingendo a repertori,
thesauri, lessici e ontologie, e adattandoli alle specifiche esigenze del
progetto e alle caratteristiche del cluster semantico a cui li si vuole
applicare.
8. Consideriamo la faccetta People. I nomi che riteniamo debbano
esservi inclusi sono quelli di figure storiche e di autori moderni di
pubblicazioni scientifiche. Per questi ultimi si deve fare riferimento a banche
dati come le bibliografie nazionali. Di grande utilità sono anche le
iniziative che effettuano lo spoglio delle riviste scientifiche. Per quanto
riguarda solamente gli studiosi attualmente in ruolo, si possono ricavare
ulteriori informazioni dal web,
utilizzando gli elenchi degli iscritti alle associazioni professionali e le
banche dati del personale universitario. Non dimentichiamo infine lo harvesting, via protocollo OAI-PMH,
dei metadati “Author” delle pubblicazioni distribuite negli Open Archives.
Analogamente, per
compilare liste di personaggi storici occorre combinare fonti diverse, senza
escludere il ricorso a repertori ed enciclopedie online, come Wikipedia, i cui dati, grazie a
iniziative come DBpedia, sono
disponibili in formato RDF (Resource Description Framework) e quindi
interpretabili da strumenti automatici[7].
9. Per la faccetta Places è stato preso in considerazione l’utilizzo di GeoNames, un database gratuito contenente oltre
otto milioni di nomi di luoghi[8], che può
essere integrato da uno strumento affidabile e completo come il Getty Thesaurus of Geographic Names (TGN). In questo caso la
principale sfida è rappresentata non tanto dal popolamento in sé,
e nemmeno dall’ambiguità di certi termini riferibili sia a persone
sia a luoghi (per esempio: Washington), quanto dal fatto che nei testi compaiono
frequenti attestazioni di località geografiche che in realtà si
riferiscono al luogo di pubblicazione di un’opera all’interno di una
citazione bibliografica. Questi nomi di luogo non sono correlati
all’argomento del testo: non forniscono perciò informazioni
rilevanti, generando invece rumore. Mediante un set di regole appositamente
predisposte, il sistema verrà quindi ‘addestrato’ a
discernere i luoghi di edizione dalle altre occorrenze di località
geografiche. Nell’impostazione della faccetta Periods sono state scelte le decadi,
in quanto i singoli anni apparivano difficili da gestire e non particolarmente
significativi. Pertanto, se in un documento compare la data “1492”,
nella faccetta avremo come fuoco la decade corrispondente, cioè
“1491-1500”. Selezionandola, l’utente restringerà la
ricerca ai testi in cui vi sono riferimenti agli anni compresi in
quell’intervallo.
Come nel caso della faccetta Places, occorre garantire una efficace
disambiguazione. Ciò ha comportato l’elaborazione di regole che
consentano di individuare, all’interno del testo, gli anni distinguendoli
da cifre relative ad altre informazioni.
10. Veniamo infine a Subjects, il cui popolamento richiede
l’adozione di criteri in parte diversi. Tra le soluzioni vagliate per
risolvere quello che si è rivelato il compito più problematico,
segnaliamo l’idea di servirsi di soggettari e classificazioni sviluppate
in ambito biblioteconomico, come i Library of
Congress Subject Headings[9]. In
alternativa, si potrebbero ottenere etichette descrittive su specifiche risorse
facendo leva sull’intelligenza collettiva
(social tagging, folksonomies): questa opzione,
potenzialmente suscettibile di applicazione anche ad altre faccette, sconta
però da un lato l’eterogeneità dei tags, dall’altro il fatto che
solo una piccola parte delle risorse del nostro corpus, estremamente
specializzato, è già stata oggetto di una precedente annotazione
su piattaforme, come Del.icio.us[10],
rivolte a un pubblico variegato. Ovviamente, le procedure per l’estrazione dei metadati
necessari per popolare le singole faccette dovranno essere automatizzate:
sarà necessario ripetere periodicamente l’indicizzazione
dell’intero archivio, impostando un sistema che garantisca
l’aggiornamento costante delle faccette stesse.
Per quanto riguarda
l’architettura complessiva del sistema, la scelta è caduta su Apache Lucene, un motore di ricerca open source stabile e dalle ottime
prestazioni[11]. In particolare, si è
rivelata decisiva la possibilità di integrare all’interno di Lucene un componente, Solr, pensato per la gestione
semantica delle informazioni. L’implementazione vera e propria resta un obiettivo da
perseguire nei futuri stadi del progetto, che richiederanno peraltro nuovi
approfondimenti e verifiche. La ricerca condotta in questa fase, relativamente
sia a questo sia agli ulteriori momenti dello studio di fattibilità, ha
avuto come finalità l’elaborazione delle linee guida generali del
progetto, nonché una verifica preliminare su sostenibilità e
coerenza delle soluzioni tecnologiche adottate per i diversi elementi di cui
è composto.
11. Il secondo problema affrontato nel corso
dell’attività di ricerca riguarda l’indicizzazione delle
risorse. A differenza dei normali motori di ricerca, RepubLit non indicizza l’intero web come fa invece Google, i cui spiders risalgono la ragnatela
seguendo il percorso tracciato dai links che connettono ciascuna pagina
alle altre. Quello di RepubLit è un approccio selettivo, che stabilisce un perimetro e al suo interno
attua delle strategie di recupero dell’informazione. Indicizzare e
classificare sono pertanto due momenti inscindibili: recuperare le risorse
implica anche ricondurle entro le tipologie previste dal progetto, le quali
consentono l’applicazione di filtri ai documenti ottenuti. Format e Language non presentano particolari
difficoltà, essendo riconosciute in modo automatico dal sistema. Per
quanto riguarda invece il filtro più importante, cioè Sources, l’attribuzione, a
ciascun item, di uno dei tre fuochi
previsti per questa faccetta deve essere effettuata manualmente, suddividendo in
tre categorie l’intero archivio.
La prima, Journals, è ovviamente relativa
alle riviste in formato elettronico. Gran parte dei periodici selezionati per
essere inclusi nell’indice di RepubLit provengono dalla Directory of Open Access Journals: le
riviste umanistiche segnalate da DOAJ sono oltre un migliaio. A queste dovrebbero aggiungersi le pagine delle riviste
in abbonamento che rendono disponibili gratuitamente gli abstracts. Per quanto riguarda i
contenuti a pagamento di queste riviste, occorre sottolineare che
l’eventuale adesione di editori commerciali al progetto implica scenari
che sono estranei ai temi trattati in questo articolo.
La seconda
categoria, Scholarly Web, è
costituita da un indice di risorse non strutturate, contenente siti web tematici che offrono studi e fonti
destinati alla ricerca scientifica. Proprio perché privo di particolari
elementi strutturanti, questo ambito ospita materiali eterogenei, che spaziano
dalla monografia ipertestuale più o meno articolata al bollettino
istituzionale, alla bibliografia, al museo virtuale, ai più diversi tipi
di archivi (fotografici, cartografici, sonori ecc.). Tra gli obiettivi che ci
siamo prefissi c’è anche quello di dare visibilità a un
dominio normalmente poco conosciuto come questo. Si è reso pertanto
necessario un ampio lavoro di selezione delle risorse telematiche, parzialmente
effettuato prima e durante la sperimentazione.
La maggior parte delle
fonti primarie, cioè le biblioteche elettroniche e le raccolte di testi
digitalizzati, rientra nella terza categoria: Digital Libraries. Parte di queste sono risorse originariamente poco
strutturate: tutti i siti che hanno le caratteristiche appropriate devono quindi
essere individuati e catalogati, grazie all’intervento di una redazione o
anche su richiesta dei responsabili. Le altre appartengono allo spazio degli
archivi istituzionali (Open Archives)
e, in prospettiva, a realtà commerciali.
12. Il terzo momento
dell’analisi è rappresentato dal problema linguistico. La gestione
di un archivio contenente documenti in molte lingue diverse è uno dei
presupposti fondamentali del progetto. La prevalenza di documenti in inglese,
riscontrabile nelle immagini precedenti, non deve pertanto far pensare a una
scelta che privilegi in modo programmatico una lingua rispetto alle altre.
L’adozione di Lucene, del resto,
garantisce che il motore di ricerca supporti tutte le principali lingue. Non vi
sono quindi limiti alla scelta dei termini da utilizzare nella query: il maggiore o minore numero di
risultati (recall) dipenderà
esclusivamente dalla quantità di documenti pertinenti disponibili
nell’idioma utilizzato.
Sono state peraltro esaminate opzioni
più sofisticate, a partire dall’ipotesi di implementare la
traduzione automatica delle queries:
in questo modo, una sola interrogazione restituirebbe risultati in varie lingue,
evitando all’utente sia di ripetere più volte la stessa ricerca sia
di replicare il successivo processo di refinement. L’ipotesi non
è stata ulteriormente approfondita a causa della sua elevata
complessità a fronte di un beneficio molto relativo (data la
capacità di scegliere correttamente le parole chiave nelle varie lingue,
propria del nostro utente ideal-tipico) ma soprattutto per la possibilità
di generare confusione in seguito a traduzioni non accurate o errate:
l’aumento del recall si
sconterebbe con una proporzionale riduzione della precision.
13. I thesauri,
di cui si è già sottolineata l’utilità nel
popolamento delle faccette, potrebbero però essere usati per tradurre
quantomeno le keywords per le quali vi
è una corrispondenza diretta con le espressioni codificate nel thesaurus.
In questo modo, per esempio, la query “Carlo Magno” inoltrerebbe al sistema anche
“Charlemagne” e “Karl der Grossen”, “London”
rimanderebbe a “Londra” e a “Londres”,
“Aufklärung” a “Enlightenment” e a
“Illuminismo”; e così via. Questa opzione richiederebbe
l’utilizzo di thesauri multilingue per i luoghi e per i personaggi storici
(il cui nome sia traducibile) ma soprattutto per gli argomenti. Anche in questo
caso, va sottolineato come l’ipotesi presa in esame lasci qualche
interrogativo aperto: se le keywords scelte non compaiono nel testo dei primi risultati restituiti (detto altrimenti,
se questi ultimi sono scritti in lingue diverse da quella della query di partenza) si rischia di
produrre un certo disorientamento nell’utente. Una possibile soluzione
consiste nell’agire sull’algoritmo, ottenendo (come in Google) un mix tra i risultati nella lingua di
partenza e i risultati in altre lingue.
Anche senza tradurre le queries, questo lavoro di
normalizzazione basato sui thesauri potrebbe essere applicato alle faccette, per
aumentare l’efficacia del raffinamento semantico. Ciò sarebbe utile
nei casi in cui si debbano gestire queries specifiche che contengono
termini intraducibili: per esempio nomi di persona o di luogo, ma anche opere
citate nel loro titolo originale o espressioni usate universalmente nella loro
lingua originale (pensiamo, a titolo esemplificativo, al “Discours de la
méthode” di Descartes e allo “Sturm und Drang”, le cui
occorrenze non sono necessariamente limitate solo a documenti francesi o
tedeschi).
In casi come questi non solo i risultati, ma anche le faccette
presenterebbero elementi in lingue diverse. Per esempio, eseguendo la query “Winston Churchill”
ci aspettiamo di ottenere documenti in differenti lingue; è pertanto
presumibile che tra i luoghi citati compaiano di volta in volta
“London”, “Londra”, “Londres”. Sorge dunque
il problema di inserire nelle faccette termini correlati che sono tra loro
sinonimi. Utilizzando thesauri multilingue è possibile accorpare i vari
fuochi in uno solo, visualizzato nella lingua che presenta il maggior numero di
occorrenze (piuttosto che in quella del termine correlato, o in quella
dell’utilizzatore).
14. Infine, la quarta direttrice seguita
riguarda l’annotazione. Un punto fermo del progetto è la scelta di
attribuire un ruolo attivo agli utenti, i quali devono poter diventare
contributori/catalogatori dei siti indicizzati dal motore di ricerca. Come
abbiamo visto, accanto a ciascun item nella pagina dei risultati è previsto un pulsante (“Tags”),
mediante il quale associare un’etichetta a quella risorsa. Ciascun utente
registrato dovrebbe poter aggiungere tags a qualsiasi documento
(utilizzando un tool sviluppato
appositamente, o mediante l’integrazione di piattaforme di social tagging esistenti, come CiteULike[12]).
Ciò consentirebbe anche di migliorare il ranking: il fatto che un sito sia
stato ‘taggato’ molte volte significa che gli utenti lo considerano
importante, pertanto questo dato può essere integrato come parametro
nell’algoritmo di ricerca di Lucene. In generale, l’obiettivo
che ci poniamo è far sì che chiunque sia autore di un articolo,
abbia pubblicato una fonte, o abbia dato qualche altro tipo di contributo
scientifico si registri e aggiunga dei contrassegni al proprio articolo o sito web. Nella scelta dei tags, gli utenti verranno assistiti da
un sistema che segnala quali sono già stati assegnati a quella risorsa da
altri utenti e suggerisce i termini semanticamente più
appropriati[13]. Il ruolo degli utenti sarà importante anche nel
segnalare nuove risorse, che saranno sfuggite nella fase iniziale di popolamento
dell’archivio o saranno state rese disponibili successivamente. La
validazione verrà attuata facendo ricorso a un sistema collaborativo: i
nuovi siti candidati a far parte dell’indice resteranno in un’area
pubblica per un certo periodo e, se otterranno un giudizio positivo da parte
della community degli utenti
registrati, verranno in seguito aggiunti all’archivio del motore di
ricerca. Anche questa, come altre opzioni, verrà comunque sottoposta a
ulteriori verifiche e riflessioni.
Il percorso di ricerca e di
sperimentazione qui descritto, attuato mediante lo strumento innovativo dello spin-off, si è dispiegato su un
terreno vasto e ha sottoposto a vaglio critico molte ipotesi, pur nei limiti
precedentemente chiariti. Nell’attuazione del progetto sono state
coinvolte e valorizzate competenze diverse e complementari, premiando
così la scelta di adottare un approccio di carattere
interdisciplinare.
Muovendo da queste premesse si potrà giudicare la
validità del progetto RepubLit,
la cui ragion d’essere – lo ribadiamo – consiste nel
realizzare strumenti pensati da ricercatori per un’utenza di
ricercatori.
Note
[1] F. Chiocchetti, «Search Wars. Per una storia dei motori di ricerca e del loro utilizzo in ambito storiografico», Cromohs, 13 (2008): 1-16, <http://www.cromohs.unifi.it/13_2008/chiocchetti_search.html> (v. paragrafo 16).
[2] Nei mesi precedenti all’avvio del progetto, Federico Meschini della De Montfort University e Salvatore Vassallo dell’Università di Udine hanno fornito a loro volta importanti contributi alla discussione preliminare. Marcello Sarino e gli altri componenti dell’Ufficio Ricerca e Relazioni internazionali dell’Università del Piemonte Orientale hanno assicurato con la loro competenza il positivo esito dell’iter amministrativo.
[3] OAI <http://www.openarchives.org/>.
[4] DOAJ <http://www.doaj.org/>.
[5] Per ulteriori informazioni sulla classificazione a faccette, ideata da S. Ranganathan, cfr. C. Gnoli, V. Marino, L. Rosati, Organizzare la conoscenza. Dalle biblioteche all’architettura dell’informazione per il web, Milano, Tecniche Nuove, 2006.
[6] SIGIR 2006 Workshop on Faceted Search, Aug 10, 2006, Seattle, <http://sites.google.com/site/facetedsearch/>.
[7] DBpedia “is a community effort to extract structured information from Wikipedia and to make this information available on the Web. DBpedia allows you to ask sophisticated queries against Wikipedia, and to link other data sets on the Web to Wikipedia data”: <http://dbpedia.org/>. Dopo l’acquisizione, nel 2010, di Metaweb, proprietario di DBpedia, da parte di Google, la società di Mountain View ha dichiarato che l’accesso alla banca dati resterà gratuito.
[8] GeoNames <http://www.geonames.org/>.
[9] LCSH <http://classificationweb.net/>.
[10] Del.icio.us <http://www.delicious.com/>.
[11] Apache Lucene <http://lucene.apache.org/>.
[12] CiteULike <http://www.citeulike.org/>.
[13] Tra le iniziative dalle finalità analoghe segnaliamo ZigTag <http://zigtag.com/>, Tagaroo <http://tagaroo.opencalais.com/>, Zemanta <http://www.zemanta.com/>.